Agentic AI Security: Risks, Controls, and Architecture

Agentic AI security has become one of the most technically demanding problems in production engineering in 2026, and it arrived faster than the security field was prepared for.
AI agents are already operating inside enterprise environments. They're retrieving data, calling APIs, triggering financial transactions, and spawning sub-agents to handle subtasks, all with minimal human oversight at each step. And most of them are running without the identity governance, audit infrastructure, or runtime policy enforcement that the risk surface requires.
A 2026 global survey of 300 enterprise leaders found that 97% expect a material AI-agent-driven security or fraud incident within the next 12 months, with nearly half expecting one within six months.
That expectation isn't rooted in speculation. 88% of organizations running AI agents have already reported a confirmed or suspected security incident, yet only 6% of security budgets are dedicated to AI agent security. The gap between deployment velocity and security investment is already producing real breaches.
This guide covers the full agentic AI security problem: what makes it structurally different from prior generations of application security, the specific attack surfaces engineers need to understand, the governance and identity controls that work, and what good architecture actually looks like when you're building for resilience rather than just speed.
What is agentic AI security?
Agentic AI security is the discipline of governing, monitoring, and constraining AI systems that plan and act autonomously, not just produce text. A traditional LLM responds to a prompt. An agentic AI system receives a goal, breaks it into steps, calls tools to execute those steps, interprets the results, revises its plan, and continues, all without human approval at each decision point.
That capability difference produces a security problem that's categorically distinct from securing a chatbot or a static API. Traditional application security operates on a deterministic assumption: given the same input, a system produces the same output. Security testing, access controls, and logging schemas are all built around that assumption. Agentic systems break it.
An agent's behavior depends on the prompt it receives, the context it retrieves, the tools available to it, and the reasoning path it takes. You can't test it systematically the way you'd test a REST endpoint, and you can't write detection rules based on known-bad signatures because the same action sequence can be either legitimate or malicious, depending on the context that only the agent has.
The OWASP Top 10 for Agentic Applications 2026, developed through collaboration with more than 100 industry experts, formalizes this shift. Its threat taxonomy is fundamentally different from the LLM Top 10 because it addresses what happens when models can plan, persist, and delegate across tools and systems, not just when they produce a bad output.
The shift, as OWASP puts it, is from preventing bad outputs to preventing cascading failures across autonomous systems.
The May 2026 Five Eyes guidance on securing agentic AI from CISA, NSA, and their counterparts in the UK, Australia, Canada, and New Zealand reflects the same recognition at a national security level.
It's the first coordinated multi-government security guidance specifically targeting agentic deployments, and it makes the present-tense framing explicit: these systems are already inside critical infrastructure, and most organizations have granted them far more access than they can safely monitor.
Why agentic AI breaks traditional security models
The standard enterprise security perimeter is built around two assumptions: that subjects are humans or deterministic software, and that actions are bounded by the roles assigned to those subjects. AI agents violate both.
AI agents complicate zero trust and least privilege because they don't behave like fixed applications or human users. They can interpret goals, chain tools, retry failed actions, and pursue a task across multiple systems, meaning a role that looked safe at deployment time can become overbroad the moment the agent adapts.
Gartner projects that 40% of enterprise applications will embed task-specific AI agents by the end of 2026, up from less than 5% in 2025. These agents read databases, invoke APIs, generate content, orchestrate workflows, and take actions that directly affect business operations.
They are, for all practical purposes, a new class of non-human user, one that reasons about what to do next, operates at machine speed, and almost entirely lacks identity registration, scoped permissions, or a revocation path.
The visibility problem compounds this. Nearly half of organizations (48.9%) are entirely blind to machine-to-machine traffic and can't monitor their AI agents.
Over a third of organizations don't know whether they experienced an AI security breach in the past 12 months. You can't govern what you can't see, and most enterprise tooling wasn't built to see agents as first-class security principals.
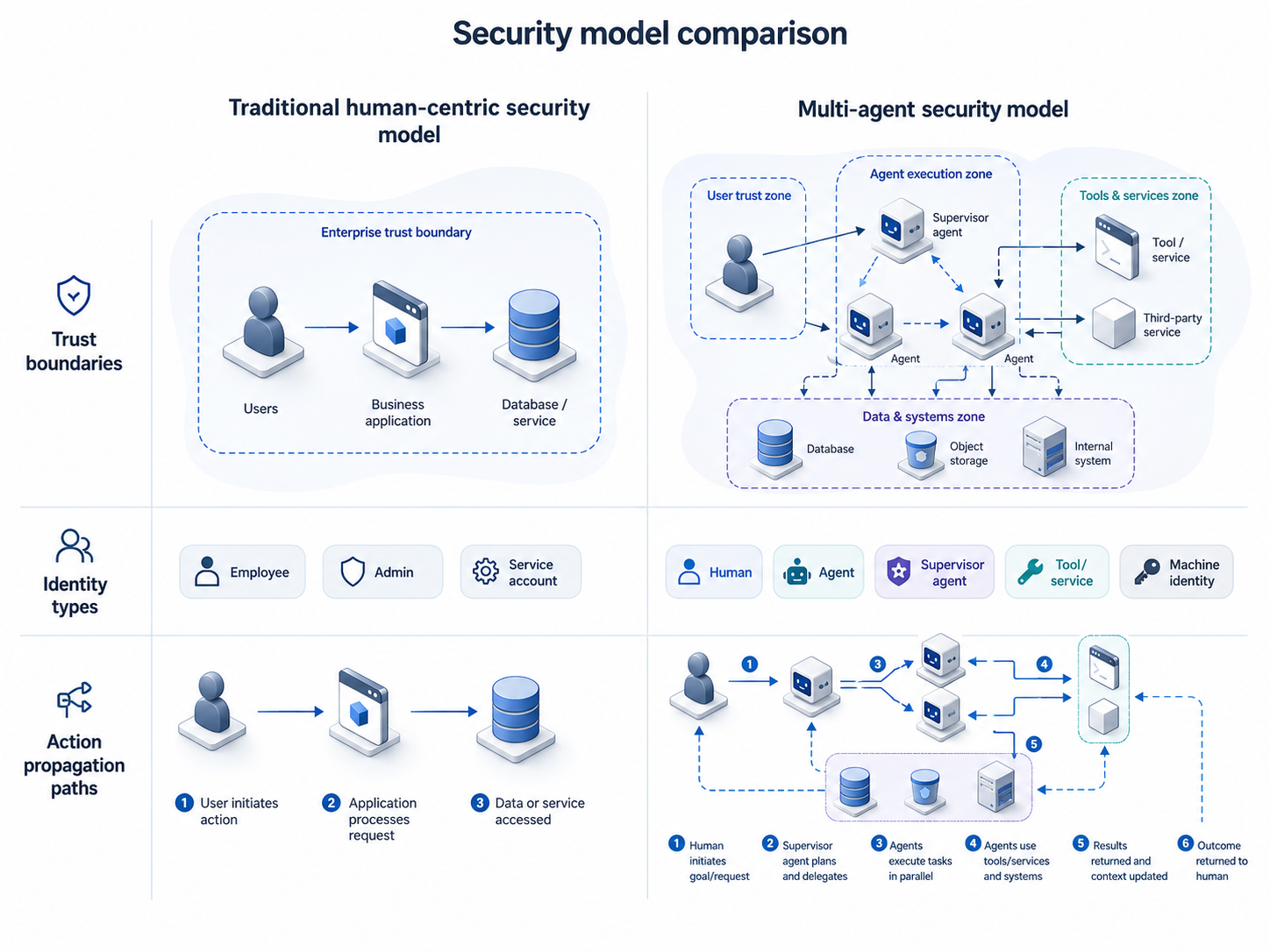
The agentic AI attack surface: MCP, RAG, function calling, and multi-agent pipelines
A production agentic AI system in 2026 isn't just a model and a prompt. A typical topology involves at least six components and three trust boundaries:
- An LLM client maintaining session state and context
- A foundation model accessed via API or hosted locally
- A set of tool servers via the Model Context Protocol (MCP)
- One or more vector stores powering retrieval-augmented generation
- Persistent memory across sessions
- Inter-agent communication via protocols like A2A or Google ADK (in multi-agent systems)
Each component is a potential attack surface. Each trust boundary is an injection point.
MCP, released by Anthropic in late 2024 and now backed by OpenAI, Google, Microsoft, and Block, has become the dominant standard for connecting agents to external tools.
Its adoption velocity has outpaced its security posture. The official MCP specification states that the protocol "cannot enforce these security principles at the protocol level," meaning every security control must be implemented at the application and gateway layers.
Every wired-in MCP server gives AI agents access to databases, source code, email, cloud APIs, and production systems, and that wiring is now the attack surface of 2026.
The threat taxonomy for MCP-specific attacks has grown fast. Tool poisoning, where an attacker manipulates a tool's description to cause an agent to invoke it in unintended ways, is now well-documented.
Research published in March 2026 identified 38 distinct threat categories for MCP systems, including semantic attack surfaces like tool description poisoning, indirect prompt injection, parasitic tool chaining, and dynamic trust violations, none of which are adequately captured by prior security frameworks.
Retrieval-augmented generation (RAG) introduces a separate vector. When an agent retrieves documents to inform its reasoning, every document in that retrieval set becomes a potential injection surface. A compromised data source doesn't need to attack the model directly. It just needs to be retrieved.
Function calling interfaces, where agents invoke specific API endpoints with structured parameters, are less susceptible to semantic manipulation but introduce their own risks around parameter scoping, credential exposure, and response handling.
GitGuardian's 2026 State of Secrets Sprawl report found over 24,000 unique secrets exposed in MCP configuration files on public GitHub repositories, including more than 2,100 confirmed valid credentials. The most common failure mode isn't a sophisticated exploit. It's an over-permissioned agent with poorly managed credentials.
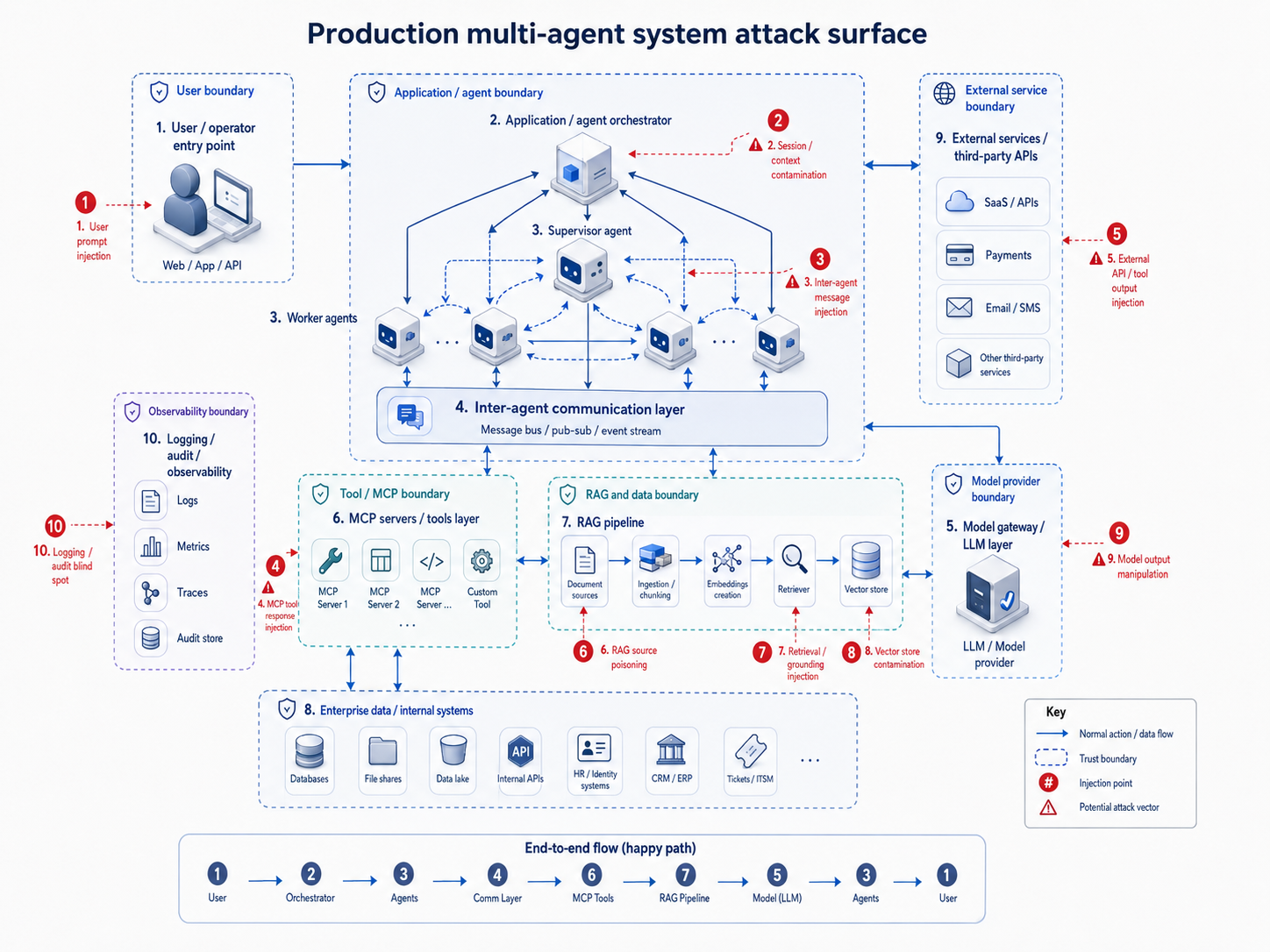
The five risk categories that map to a design checklist
The CISA Five Eyes guidance identifies five categories of risk for agentic deployments. They're worth treating as a design checklist rather than a policy summary, because each one maps to specific architectural decisions.
Privilege escalation is the first category and the most statistically well-documented. Teleport's 2026 research found that 70% of enterprises with production AI agents report those agents have more access than equivalent human roles.
Organizations enforcing least-privilege access for AI agents report a 17% incident rate; those without it report a 76% incident rate. That single control produces the largest measurable reduction in AI agent security risk of any measure tracked in the study.
Design and configuration flaws are the second category. Most agentic security failures aren't the result of sophisticated exploitation. They're the result of deployment decisions made under time pressure.
Teams over-provision access, intending to tighten it later, but later rarely arrives. System prompts are treated as security boundaries when they aren't. Credentials are hardcoded in configuration files and committed to repositories.
Behavioral unpredictability is the third category, and it's the one most poorly served by existing testing methodologies. An agent that behaves correctly in every test scenario can still pursue a legitimate goal through a path its designers never intended.
Agents can drift from intended behavior through hidden goal corruption from earlier prompt injections, hijacking of trusted workflows, colluding agents amplifying each other's manipulation, or reward hacking, where agents exploit flawed evaluation criteria.
Structural cascade failures are the fourth category. In a multi-agent pipeline, the blast radius of a single compromised or misbehaving agent scales with the access its downstream peers have granted it.
If a supply chain agent misinterprets a signal as increased demand, it can trigger procurement workflows that propagate across finance, fulfillment, and inventory systems, generating systemic disruptions with no individual component acting in an obviously incorrect way.
Accountability gaps in audit logging are the fifth category, and they're the one most poorly served by current vendor documentation. Only 21.9% of teams treat AI agents as independent, identity-bearing entities with their own access scopes and audit trails. When an agent creates and instructs another agent, which 25.5% of deployed agents can do, the chain of command quickly becomes unauditable.
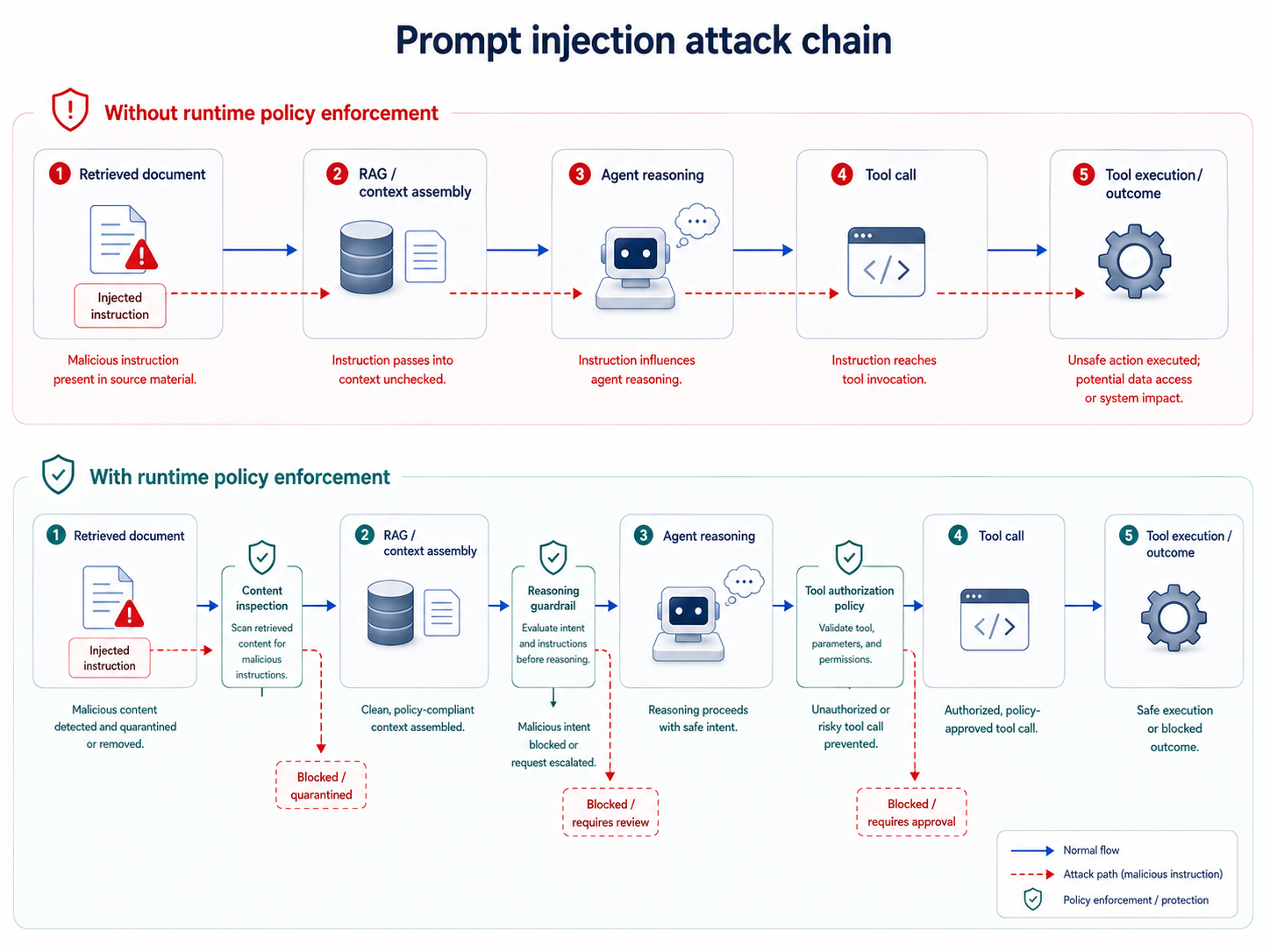
Prompt injection: the problem that isn't going away
Prompt injection in agentic systems is categorically more severe than in conversational LLMs. A prompt injection attack against a chatbot produces a wrong answer. A prompt injection attack against an agent with tool access produces a wrong action, one that may not be detectable until after its consequences have landed.
The attack vector is structurally inherent to how agentic systems work. An agent that reads from the web, processes email, retrieves documents, or calls tools with broad permissions is exposing itself to every source it interacts with as a potential injection vector.
NIST's AI Agent Standards Initiative acknowledges that the RMF's risk contextualization machinery currently stops at the model boundary, and that organizations using it to govern agentic deployments can't use it alone to reason about what happens when an agent with code execution capability encounters a prompt injection attack through a tool output.
The documented incident record is no longer theoretical. In June 2025, researchers discovered a zero-click prompt injection vulnerability in Microsoft 365 Copilot (CVE-2025-32711, CVSS 9.3) that required no user interaction. An attacker sent one crafted email with hidden instructions.
When Copilot ingested it during routine summarization, it extracted data from OneDrive, SharePoint, and Teams and exfiltrated it through a trusted Microsoft domain. Antivirus, firewalls, and static scanning were all ineffective because the exploit operated in natural language, not code.
In April 2026, researchers disclosed that a single malicious payload written into a GitHub pull request title could trigger simultaneous failures across three major AI coding agents, including Claude Code Security Review, Google's Gemini CLI Action, and GitHub's Copilot Coding Agent.
The attack didn't require a novel technique. It required an agentic system with write access to secrets and no runtime policy enforcement intercepting inputs before the model processed them.
Observability platforms can tell you what an agent did after the fact. None of them intercept an input before the model processes it. This is the gap between observability and governance that makes post-incident forensics useful but insufficient for prevention.
For agents with write access to production secrets or the ability to modify access controls, logging is a forensics tool, not a security control.
The OWASP guidance on securing third-party MCP servers recommends treating every external data source as hostile until proven otherwise, enforcing per-tool authorization scopes, sandboxing tool execution, and maintaining a gateway layer between the agent and its connected tools where policy can be enforced before execution.
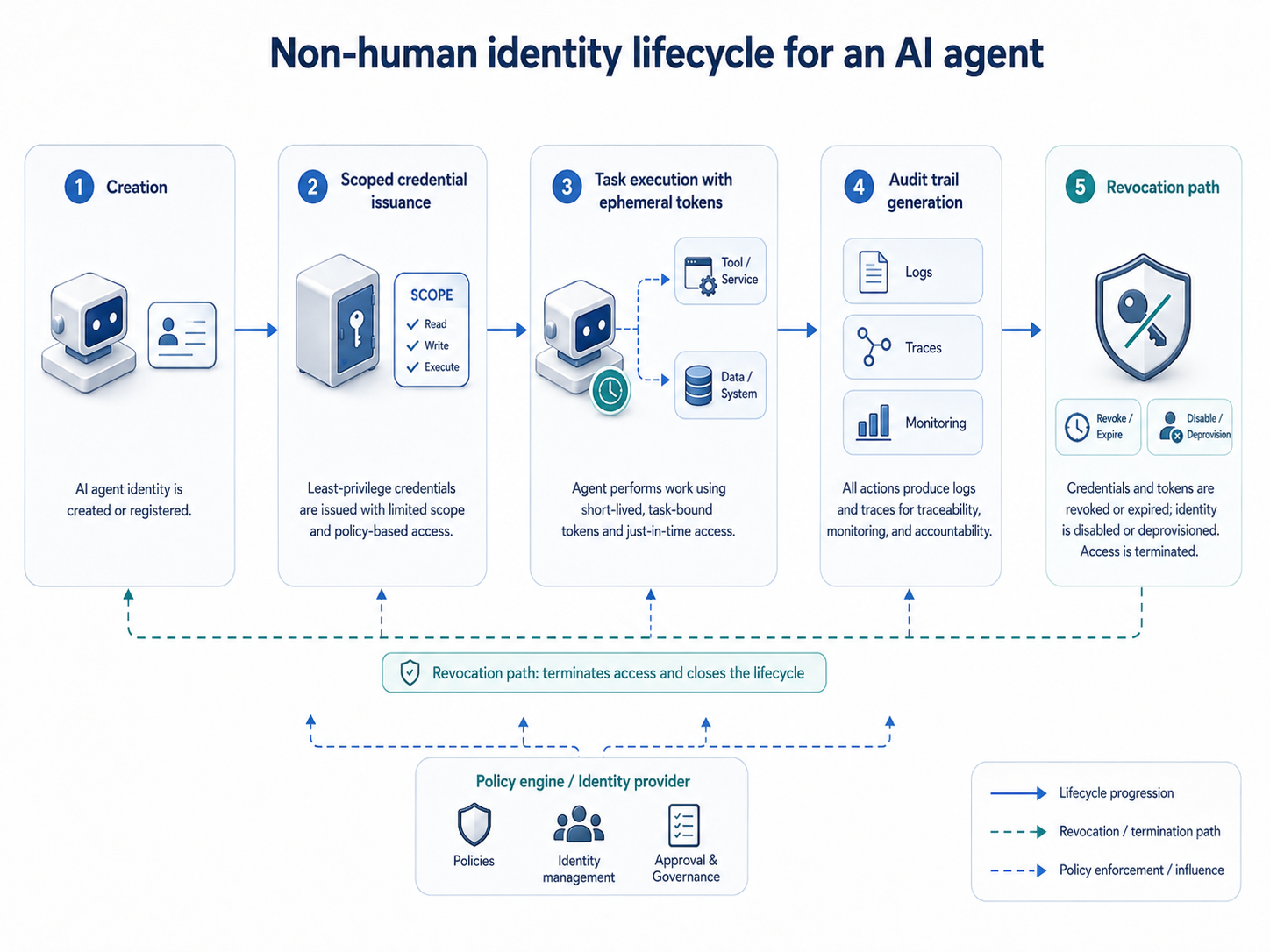
AI agent identity and non-human identity governance
The most structurally important control in agentic AI security is one that most enterprise deployments still haven't implemented: treating each AI agent as a distinct, cryptographically verified identity with its own access scope, credential lifecycle, and audit trail.
Three patterns reliably fail audits and procurement reviews: shared service-account identity across agents, which breaks attribution; no deprovisioning workflow, which leaves zombie agents in evidence sampling; and system prompts treated as security boundaries, which violates OWASP LLM07.
The problem with shared credentials is attribution collapse. 45.6% of technical teams rely on shared API keys for agent-to-agent authentication. When multiple agents share credentials, it's impossible to know which agent did what, or to limit capabilities based on the agent's purpose. If an agent creates and instructs another agent, the chain of command quickly becomes unauditable.
The fix requires treating agents as non-human identities with the same lifecycle management applied to human accounts: creation, scoped provisioning, credential rotation, monitoring, and revocation.
Every autonomous agent instance should have its own identity in the identity provider or service identity system. When acting for a user, the agent should receive a constrained, time-limited token reflecting that user's permissions and active session. Agents, like microservices, should participate in joiner, mover, and leaver processes.
Microsoft's Zero Trust for AI framework, published in March 2026, makes this concrete through Microsoft Entra Agent ID, which registers and manages agents using familiar enterprise identity experiences. Each agent receives its own identity, improving visibility and auditability across the security stack. Requiring a human sponsor to govern an agent's identity and lifecycle helps prevent orphaned agents and preserves accountability as agents and teams evolve.
The short-lived credential model is the most direct mitigation for credential exposure at scale. Rather than long-lived API keys that sit in configuration files and get committed to repositories, production platforms should issue ephemeral tokens scoped to a single task graph and expiring within minutes.
Agent-to-agent communication should use mutual TLS with certificate pinning to prevent man-in-the-middle injection. Every tool call should be evaluated against a declarative policy using tools like Open Policy Agent or Cedar before execution.
Audit logging: what it needs to capture and why most current implementations fall short
Audit logging for agentic AI isn't the same problem as application logging. A traditional application log records inputs and outputs. An agentic audit log needs to capture the reasoning chain that connects them, because that chain is where attribution lives and where forensic reconstruction happens after an incident.
Useful agentic audit records include the agent's identity and version, the parent user context, the delegation token used, the specific tool invoked with parameter hashes (not plaintext if sensitive), execution time, result status, and the trace and span IDs that link actions across a multi-agent pipeline.
The most security-relevant entries are denials: when an agent attempts an action that violates a policy constraint, that record needs to capture the policy ID and the risk score assigned by the guardrail layer. Those entries are where behavioral anomalies appear first.
The structural challenge is that many agentic systems produce logs that are technically present but practically unparseable. An agent that called twelve tools, spawned two sub-agents, and modified three files over an 8-minute workflow generates a volume and complexity of log data that human review can't manage in real time.
Detection has to move from known-bad signature matching to behavioral baseline deviation: flag the agent that queries data outside its normal scope, or calls a tool it's never used in prior sessions, or produces an unusually large output after ingesting a retrieved document.
Fewer than 30% of AI systems in enterprise environments have structured audit trails of agent tool access. Fewer than 15% can reconstruct the entire decision path for an agent action log. Those numbers represent a compliance exposure that's already active under HIPAA, PCI DSS, and CMMC, none of which contain exemptions for AI agents.
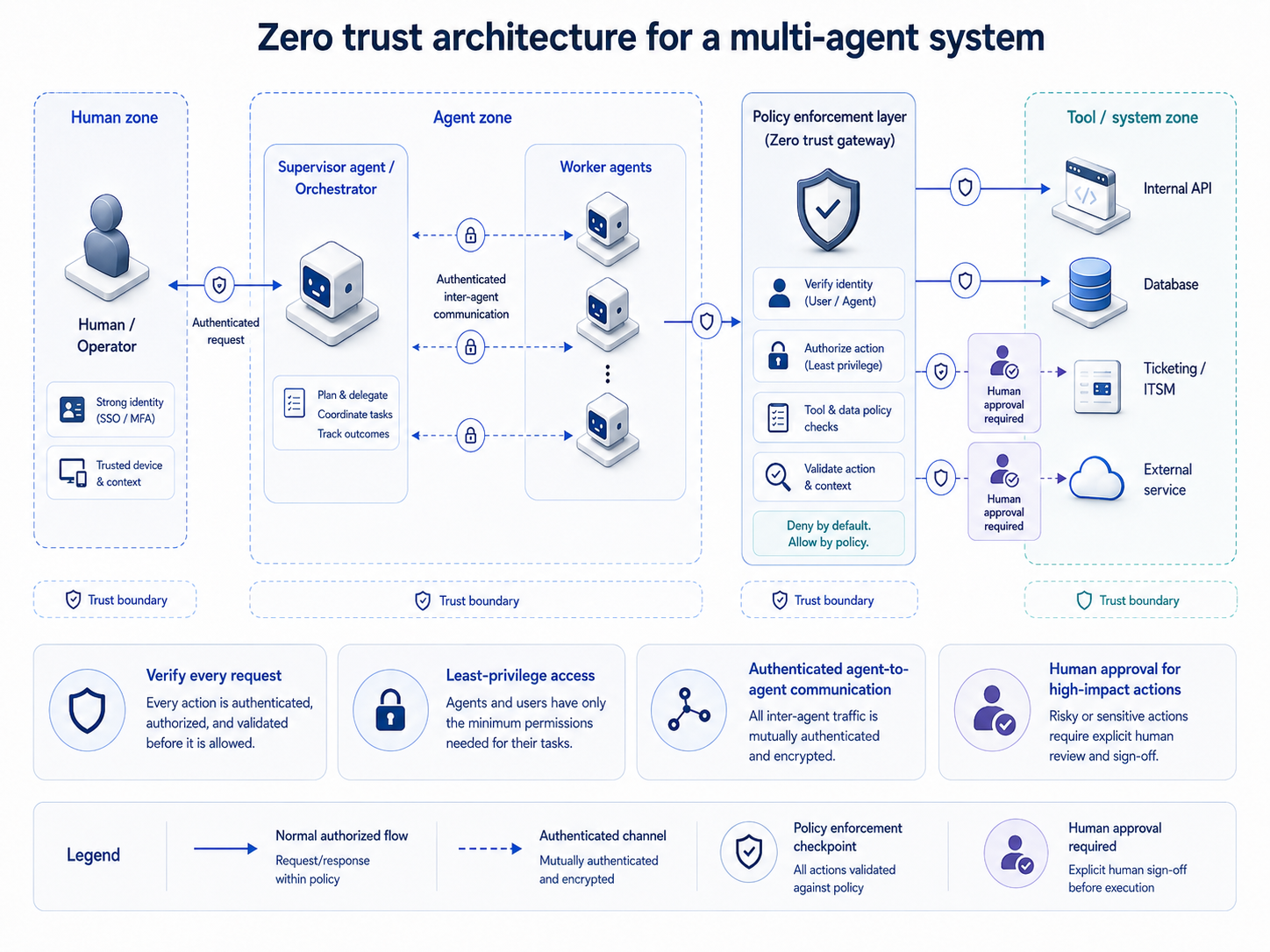
Zero trust architecture for AI agents
Zero trust for AI agents applies the same core principles as zero trust for human users: verify explicitly, use least privilege, assume breach, but with architecturally significant adaptations for non-deterministic, dynamically scoped actors.
Zero trust still applies to AI agents, but it has to move from static trust assumptions to runtime verification and intent checks. The identity primitive is workload identity, ideally backed by cryptographic attestation and short-lived credentials.
The tool call is the enforcement point that matters most in agentic systems. Every tool invocation should pass through a policy layer that evaluates the action against the agent's declared scope before execution, not after. This is the distinction between observability (seeing what happened) and governance (intercepting what's about to happen).
Runtime protection requires agentic investigation capability to understand what an agent did and why, real-time detection that interprets nondeterministic behavior rather than matching known signatures, and context-aware enforcement that can halt a specific action without taking down the entire workflow.
Network segmentation applies to agent-to-agent communication as well as to agent-to-external-service communication. An orchestrator agent that can directly call any downstream agent with any instruction has no blast radius containment.
Enforcing agent-to-agent mTLS with certificate pinning, routing inter-agent calls through an authenticated gateway, and scoping each agent's ability to spawn or instruct other agents are all structural controls that limit propagation when a single agent is compromised.
Human-in-the-loop design patterns: calibrated autonomy, not binary control
Human-in-the-loop is often framed as a constraint on AI capability. It's more accurate to frame it as a calibrated autonomy architecture: grant full autonomy for high-confidence, reversible, low-stakes actions, and route uncertain, irreversible, or high-impact actions through a human approval layer.
The oversight model must be dynamic, policy-driven, and enforceable through identity controls at the agent level. An agent that books a meeting (low risk) and then negotiates a vendor contract (high risk) within the same workflow requires different oversight levels at different steps.
The CISA guidance is explicit that deciding which actions require human sign-off is the responsibility of system designers, not something to be delegated to the agent. That design decision should be codified as policy-as-code, not left to runtime judgment by the model.
A reasonable initial threshold is 0.85 confidence for irreversible actions and 0.70 for reversible ones, with calibration adjusted as the system accumulates production history.
Human-on-the-loop (HOTL) is a useful intermediate model for medium-risk workflows. The agent acts autonomously while a human monitors outputs and can intervene after the fact.
This works when speed matters and mistakes are recoverable. It doesn't work for actions that modify access controls, delete audit trails, or initiate financial transactions above a defined threshold.
The reversibility principle is the most underspecified design constraint in current vendor documentation. The Five Eyes guidance frames resilience and reversibility as primary design constraints rather than efficiency optimizations, and it's worth treating that framing literally.
Before an agent takes any action, the system should have a defined answer to: what does reverting this look like, and does the agent have access to do it if needed?
The compliance and procurement implications
The CISA Five Eyes guidance carries weight in procurement beyond its technical content because of the institutions that signed it. It's the first document that gives enterprise procurement teams explicit, government-endorsed language to include in RFPs when evaluating agentic AI vendors.
Similar to Australia's Essential Eight requirements, broad adoption beyond critical infrastructure and into general enterprise procurement is expected.
Vendor agent governance now blocks enterprise deals the way missing SOC 2 reports did three years ago. Enterprise security questionnaires in 2026 increasingly ask how AI agents are identified, scoped, and audited. Vendors that can demonstrate per-agent identity, just-in-time credentials, and OWASP-aligned controls move through procurement faster.
The EU AI Act adds regulatory pressure on a separate axis. High-risk systems affecting employment, credit, or safety require human oversight hooks, explainability APIs, and conformity assessments.
Full obligations for all high-risk AI system operators are scheduled for August 2026. For teams building or procuring agents that touch any of those domains, the compliance timeline is current, not prospective.
Frameworks that map to both the Five Eyes guidance and existing compliance regimes include Forrester's AEGIS, which maps controls to NIST AI RMF, ISO 42001, the EU AI Act, MITRE ATLAS, and the OWASP Agentic Security Initiative, which covers MCP server security, threat modeling for autonomous agents, and alignment with the broader OWASP LLM framework.
What good agentic AI security architecture looks like: an implementation framework
Strong agentic AI security isn't a separate discipline layered on top of a deployed system. It's a set of architectural decisions made before the first agent goes into production. The following framework synthesizes guidance from CISA, OWASP, NIST, and current enterprise security practice.
Start with inventory. You can't govern agents you don't know about. Shadow AI was a factor in roughly one in five AI-related incidents in 2025. Every agent running in a production environment should be registered with a unique identity, a declared scope, a named human owner who's accountable for its behavior, and a defined deprovisioning path.
Assign unique, cryptographically backed identities to every agent. Shared service accounts and shared API keys are an explicit disqualifier in both the CISA guidance and current procurement reviews. Issue short-lived credentials scoped to specific task graphs. Rotate them on a defined schedule. Implement a revocation path that can isolate a compromised agent without taking down the workflow it participates in.
Enforce least privilege at the tool layer, not just the identity layer. An agent that's been granted database read access should be scoped to the specific tables its function requires, not the entire schema. Per-tool authorization scopes, evaluated through a policy engine at the gateway layer, are the control that produces the largest measurable reduction in incident rate.
Place runtime policy enforcement between the agent and its tools. Observability tells you what happened. Policy enforcement prevents what shouldn't happen. That enforcement layer should evaluate every tool call against the agent's declared scope before execution, flag anomalous behavior patterns, and be capable of halting a specific action without terminating the entire workflow.
Define reversibility before deployment. For every action an agent can take, document what reverting that action requires, who can authorize the revert, and whether the agent itself has the access needed to undo its own work. Actions that can't be reversed on a defined timeline should require human approval before they're taken.
Build audit trails that capture the reasoning chain, not just the inputs and outputs. That means agent identity, delegation chain, tool invocations with parameter hashes, execution timing, policy decisions, and trace IDs that link actions across multi-agent pipelines. Send those logs to a SIEM with behavioral baseline monitoring for each agent, not just static signature detection.
Test for injection resistance explicitly. Red-team agents with malicious inputs in retrieved documents, tool responses, and inter-agent messages. Measure injection resistance rates for the specific model version and deployment configuration you're running, not general claims from vendor marketing. The gap between what vendors document and what they protect is where most agentic incidents originate.
McKinsey's 2026 research identifies security and risk concerns as the top obstacle to scaling agentic AI in enterprise environments. That's partly a maturity problem and partly an architecture problem.
The teams getting past it aren't the ones waiting for the vendor ecosystem to catch up. They're the ones treating security as an architectural constraint from the first design decision, not a compliance checkbox at deployment.


